
DevKim
[webtooniverse] 내가 만든 서비스의 성능을 개선해보자 (1) - Scale out 본문
[webtooniverse] 내가 만든 서비스의 성능을 개선해보자 (1) - Scale out
on_doing 2021. 8. 17. 20:09본 포스팅은 성능 테스트를 진행하면서 겪은 이슈와 이를 해결해나가며 겪은 개인적인 경험을 공유하고자 작성하였습니다.
고로 포스팅에 잘못된 점은 지적해주시면 감사하겠습니다 :)
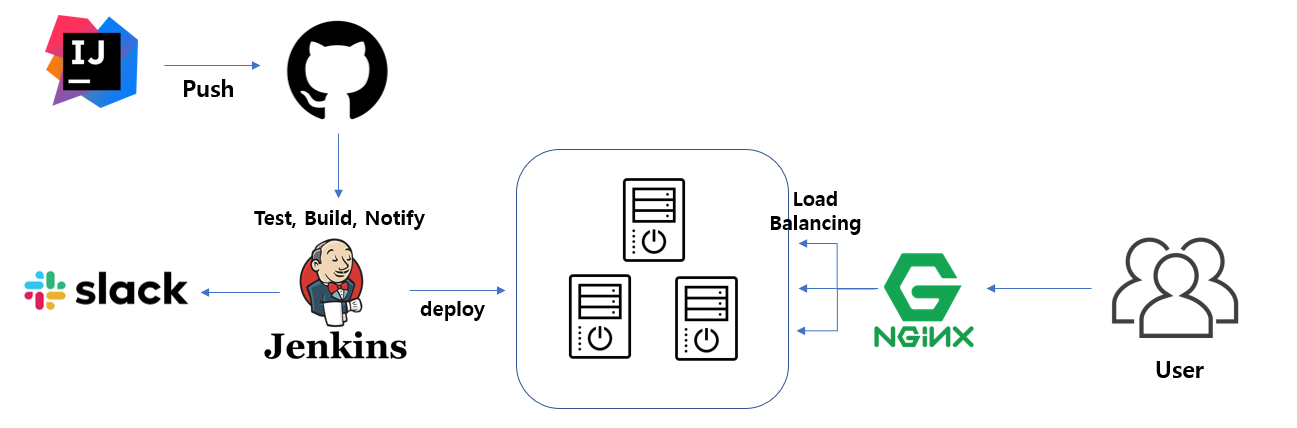
[ 공통 테스트 환경 ]
- 가벼운 테스트 툴을 빠르게 사용하기 위해 Artillery를 사용하였습니다.
- 2vCPU, 2GB 메모리 서버 3대로 Scale out을 하였으며 Redis 서버 사양은 1vCPU, 2GB 메모리 서버 한대입니다.
[ 테스트 환경 #1 ]
- 메인 페이지의 웹투니버스/네이버/카카오 랭킹 기능을 테스트하였습니다.
- Redis 캐시를 이용해 각 조회 기능을 빠르게 가능하도록 구현했습니다.
[ 시나리오 #0 ]
-duration 300 arrivalRate 1
<웹투니버스>


2. 네이버/카카오

[ 시나리오 #1 ]
1. 총 1만명의 vuser
- duration 100, arrivalRate 100
[ scale-out 전 ]
[ scale-out 후 ]


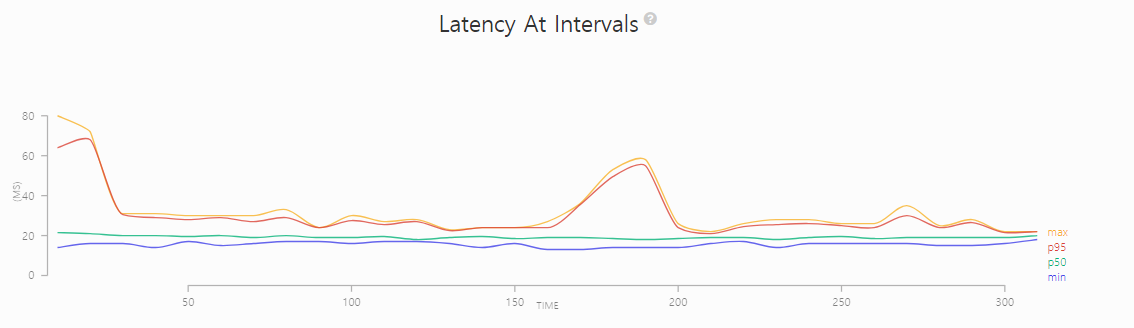
조금 이상한 점을 발견했다.
분명 로드밸런서를 이용하여 세개에 모두 똑같이 부하를 주고 있는데
CPU 사용량이 워커 인스턴스1에 몰림 현상이 발생하고 있다.

gcp에서 제공하는 CPU 사용률을 봐도 워커인스턴스 1이 압도적으로 높다.
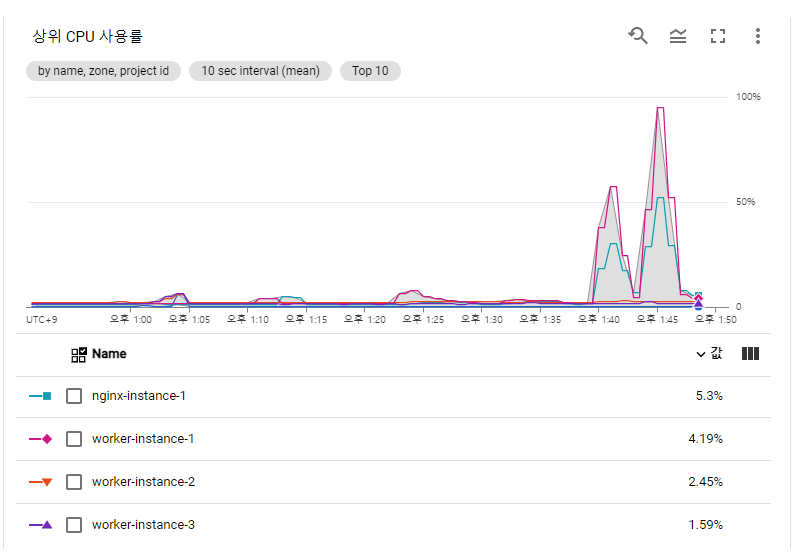
현재 아무런 알고리즘을 따로 설정하지 않았기 때문에 라운드 로빈 방식이 기본값으로 적용되어있을 것이다.
요청이 들어온 시점에 가장 적은 연결상태를 보이는 서버에 우선적으로 트래픽을 배분하는 최소 연결 방식으로 변경해보자
least_conn;
[ 최소 연결 방식 적용 후 ]
cpu 사용량도 적절히 분배되고 있고,

Latency가 149까지 떨어졌다.


[ 시나리오 #2 ]
2. 총 5만명의 vuser
- duration 300, arrivalRate 100
- duration 100 arrivalRate 200 ramp up
[ scale-out 후 ]
scale-out 전보다 Latency가 요동치는 시점이 많아졌고 89건의 요청에 대해 TIMEOUT까지 발생하게 되었다.


< 접근 >
톰캣에 직접 요청을 하니까 오히려 모든 요청이 실패하지 않았고, Latency 0-200 선에서 마무리가 되는 것을 확인했다.
이렇게 된다면, 이건 nginx의 문제라고 판단을 했고
nginx의 에러 로그를 살펴보았다.

Too many open files 라는 에러를 계속 내뿜고 있었다. 구글링 해서 찾아보니 이런 오류는 프로세스가 OS에 요청할 수 있는 리소스의 개수에 limit이 있고, 프로세스가 그 제한을 넘었기 때문이라고 한다.
해결책은 limit을 늘려주는 것으로 해결할 수 있다.
nginx의 PID
ps -aux | grep nginxworker process들의 현재 nofile limit을 확인해보자
sudo prlimit --nofile --output RESOURCE,SOFT,HARD --pid {워커의 pid}생각보다 굉장히 낮게 설정이 되어있다

최대 몇까지 높일 수 있는지 확인해보자
sudo cat /proc/sys/fs/file-max
10만 정도까지로 올려보자
sudo prlimit --nofile=100000 --pid={id}
[ 최소 연결 방식 적용 후 ]

p99 기준 Latency 139까지 떨어졌고, Latency도 몇 번 튀긴 하지만 그 전보다는 안정적인 Latency로 나왔다.



[ 시나리오 #3 ]
3. 총 10만명의 vuser
- duration 200, arrivalRate 200
- duration 100 arrivalRate 300 ramp up
- duration 100 arrivalRate 300 sustained
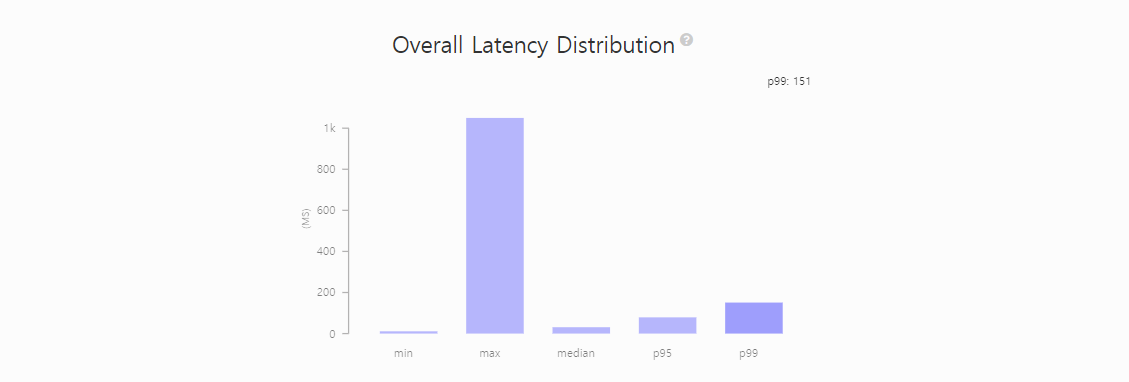
[ scale-out 후 ]
Latency p99 기준 151ms, 그 전보다 많이 안정된 것을 확인할 수 있다.

[ 테스트 환경 #2 ]
- 추천 페이지의 웹툰 평론가 추천, 완결 작품 추천 기능을 테스트하였습니다.
- 업데이트가 빈번한 곳이기 때문에 Redis 캐시를 적용하지 않았습니다.
- 웹툰 이미지 데이터가 많은 곳이라 부하가 많을 것으로 예상됩니다.
- Target 서버 사양은 2vCPU, 2GB 메모리 서버 한대이고 Redis 서버 사양은 1vCPU, 2GB 메모리 서버 한대입니다.
[ 시나리오 #1 ]
-duration 300 vuser1
[ 결과 ]
???? 더 안 좋아짐...왓 더


[ 최소 연결 적용 후 ]

p99기준 Latency 55.5
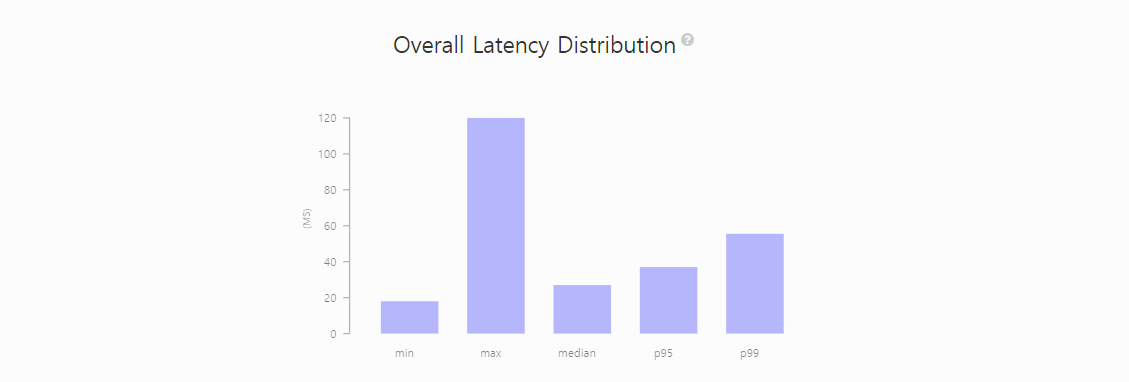

[ 시나리오 #2 ]
1. 총 1만명의 user
- duration 100, vuser 100
[ scale-out 전 ]
[ scale-out 후 ]
Latency가 25.5ms 정도로 굉장히 낮게 나왔으며, 튀는 값 없이 비교적 안정적인 형태를 유지하는 것을 확인할 수 있다.
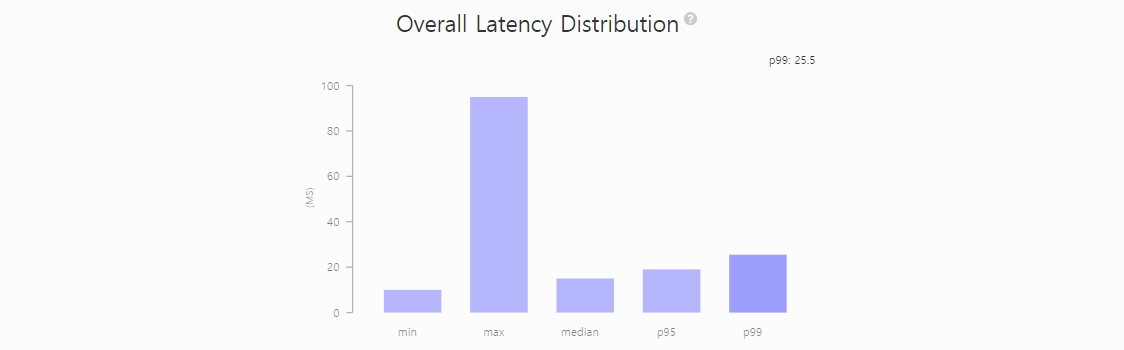

[ 시나리오 #3 ]
2. 총 5만명의 user
- duration 300, vuser 100
- duration 100 vuser 200 ramp up
[ scale-out 전 ]
[ scale-out 후 ]
전과 다르게 모든 요청에 대해 성공했고 ramp up 후에도 비교적 안정적인 수치를 보였다.



3. 총 10만명의 vuser
- duration 200, vuser 200
- duration 100 vuser 300 ramp up
- duration 100 vuser 300 sustained
[ scale-out 전 ]
[ scale-out 후 ]



I/O burst로만 이루어진 API도 scale out으로 해결할 수 있을까?
[ 테스트 환경 #3 ]
- 톡톡 페이지의 톡톡 작성, 조회 기능을 테스트하였습니다.
- 게시글 데이터 10만개를 가공하여 테스트 데이터로 사용하였습니다.
* 출처 : Naver sentiment movie corpus v1.0
[ 시나리오 #0 ]
-duration 300 arrivalRate 1
[ 시나리오 #1 ]
1. 총 1만명의 vuser
- duration 100, arrivalRate 100

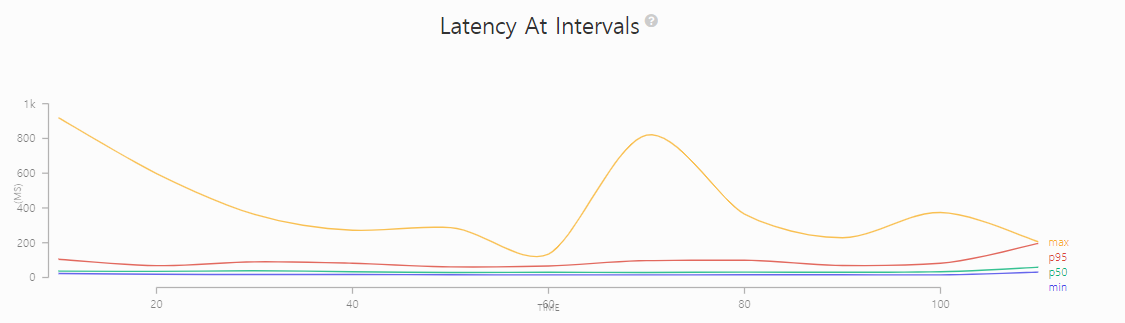
[ 시나리오 #2 ]
2. 총 5만명의 vuser
- duration 300, arrivalRate 100
- duration 100 arrivalRate 200 ramp up
DB CPU 사용률이 급격히 증가했다.

다 통과했다



[ 시나리오 #3 ]
3. 총 10만명의 vuser
- duration 200, arrivalRate 200
- duration 100 arrivalRate 300 ramp up
- duration 100 arrivalRate 300 sustained
[ 결과 ]


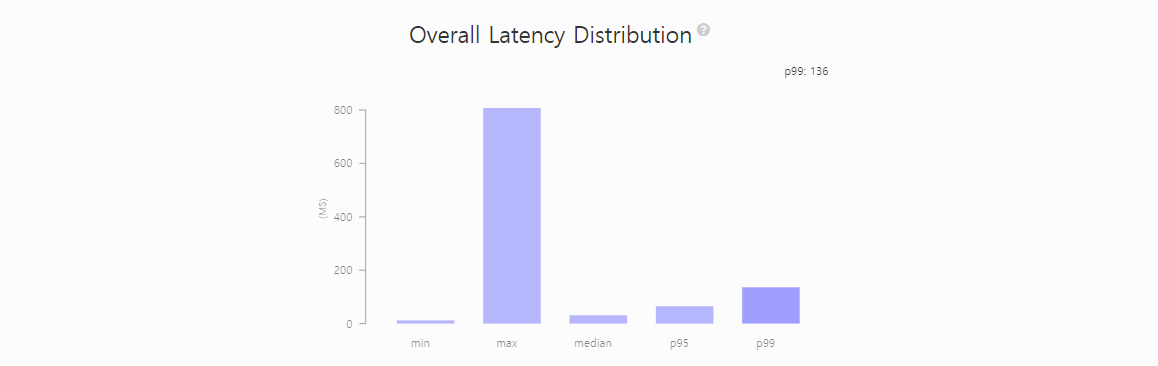

[ 시나리오 #4 ]
현재 총 20만개 이상의 데이터가 더미 데이터로 쌓여있는 상태에서
글을 더 작성하고, 목록을 가져와보자 더 스트레스를 줘보자

3. 총 10만명의 vuser
- duration 200, arrivalRate 200
- duration 100 arrivalRate 300 ramp up
- duration 100 arrivalRate 300 sustained
쓰기,읽기 둘다


'Spring Project > Webtooniverse' 카테고리의 다른 글
| [Webtooniverse] 서버 부하를 줄이기 위한 캐싱 적용 (0) | 2021.08.20 |
|---|---|
| [Refactor] Querydsl Result Aggregation 사용하여 query 개수 감소 및 코드 단순화 (0) | 2021.08.19 |
| [ webtooniverse ] 내가 만든 서비스는 얼마만큼의 사용자를 견딜 수 있을까? - 서버 스트레스 테스트 (1) (0) | 2021.08.17 |
| [ webtooniverse ] 프로젝트 구조 변경 - 무중단 배포 도입 (0) | 2021.08.16 |
| [Refactor] 쿼리 성능 개선 (0) | 2021.08.12 |



